
My first intuition about Bayes Theorem was “take evidence and account for false positives”. Does a lab result mean you’re sick? Well, how rare is the disease, and how often do healthy people test positive? Misleading signals must be considered.
This helped me muddle through practice problems, but I couldn’t think with Bayes. The big obstacles:
Percentages are hard to reason with. Odds compare the relative frequency of scenarios (A:B) while percentages use a part-to-whole “global scenario” [A/(A+B)]. A coin has equal odds (1:1) or a 50% chance of heads. Great. What happens when heads are 18x more likely? Well, the odds are 18:1, can you rattle off the decimal percentage? (I’ll wait…) Odds require less computation, so let’s start with them.
Equations miss the big picture. Here’s Bayes Theorem, as typically presented:
 = \frac{\Pr(\mathrm{X}|\mathrm{A})\Pr(\mathrm{A})}{\Pr(\mathrm{X|A})\Pr(A)+ \Pr(\mathrm{X|\sim A})\Pr(\sim A)}}}")
It reads right-to-left, with a mess of conditional probabilities. How about this version:
original odds * evidence adjustment = new odds
Bayes is about starting with a guess (1:3 odds for rain:sunshine), taking evidence (it’s July in the Sahara, sunshine 1000x more likely), and updating your guess (1:3000 chance of rain:sunshine). The “evidence adjustment” is how much better, or worse, we feel about our odds now that we have extra information (if it was December in Seattle, you might say rain was 1000x as likely).
Let’s start with ratios and sneak up to the complex version.
Caveman Statistician Og
Og just finished his CaveD program, and runs statistical research for his tribe:
- He saw 50 deer and 5 bears overall (50:5 odds)
- At night, he saw 10 deer and 4 bears (10:4 odds)
What can he deduce? Well,
original odds * evidence adjustment = new odds
or
evidence adjustment = new odds / original odds
At night, he realizes deer are 1/4 as likely as they were previously:
10:4 / 50:5 = 2.5 / 10 = 1/4
(Put another way, bears are 4x as likely at night)
Let’s cover ratios a bit. A:B describes how much A we get for every B (imagine miles per gallon as the ratio miles:gallon). Compare values with division: going from 25:1 to 50:1 means you doubled your efficiency (50/25 = 2). Similarly, we just discovered how our “deers per bear” amount changed.
Og happily continues his research:
- By the river, bears are 20x more likely (he saw 2 deer and 4 bears, so 2:4 / 50:5 = 1:20)
- In winter, deer are 3x as likely (30 deer and 1 bear, 30:1 / 50:5 = 3:1)
He takes a scenario, compares it to the baseline, and computes the evidence adjustment.
Caveman Clarence subscribes to Og’s journal, and wants to apply the findings to his forest (where deer:bears are 25:1). Suppose Clarence hears an animal approaching:
- His general estimate is 25:1 odds of deer:bear
- It’s at night, with bears 4x as likely => 25:4
- It’s by the river, with bears 20x as likely => 25:80
- It’s in the winter, with deer 3x more likely => 75:80
Clarence guesses “bear” with near-even odds (75:80) and tiptoes out of there.
That’s Bayes. In fancy language:
- Start with a prior probability, the general odds before evidence
- Collect evidence, and determine how much it changes the odds
- Compute the posterior probability, the odds after updating
Bayesian Spam Filter
Let’s build a spam filter based on Og’s Bayesian Bear Detector.
First, grab a collection of regular and spam email. Record how often a word appears in each:
spam normal
hello 3 3
darling 1 5
buy 3 2
viagra 3 0
...
(“hello” appears equally, but “buy” skews toward spam)
We compute odds just like before. Let’s assume incoming email has 9:1 chance of spam, and we see “hello darling”:
- A generic message has 9:1 odds of spam:regular
- Adjust for “hello” => keep the 9:1 odds (“hello” is equally-likely in both sets)
- Adjust for “darling” => 9:5 odds (“darling” appears 5x as often in normal emails)
- Final chances => 9:5 odds of spam
We’re learning towards spam (9:5 odds). However, it’s less spammy than our starting odds (9:1), so we let it through.
Now consider a message like “buy viagra”:
- Prior belief: 9:1 chance of spam
- Adjust for “buy”: 27:2 (3:2 adjustment towards spam)
- Adjust for (“viagra”): …uh oh!
“Viagra” never appeared in a normal message. Is it a guarantee of spam?
Probably not: we should intelligently adjust for new evidence. Let’s assume there’s a regular email, somewhere, with that word, and make the “viagra” odds 3:1. Our chances become 27:2 * 3:1 = 81:2.
Now we’re geting somewhere! Our initial 9:1 guess shifts to 81:2. Now is it spam?
Well, how horrible is a false positive?
81:2 odds imply for every 81 spam messages like this, we’ll incorrectly block 2 normal emails. That ratio might be too painful. With more evidence (more words or other characteristics), we might wait for 1000:1 odds before calling a message spam.
Exploring Bayes Theorem
We can check our intuition by seeing if we naturally ask leading questions:
Is evidence truly independent? Are there links between animal behavior at night and in the winter, or words that appear together? Sure. We “naively” assume evidence is independent (and yet, in our bumbling, create effective filters anyway).
How much evidence is enough? Is seeing 2 deer & 1 bear the same 2:1 evidence adjustment as 200 deer and 100 bears?
How accurate were the starting odds in the first place? Prior beliefs change everything. (“A Bayesian is one who, vaguely expecting a horse, and catching a glimpse of a donkey, strongly believes he has seen a mule.”)
Do absolute probabilities matter? We usually need the most-likely theory (“Deer or bear?”), not the global chance of this scenario (“What’s the probability of deers at night in the winter by the river vs. bears at night in the winter by the river?”). Many Bayesian calculations ignore the global probabilities, which cancel when dividing, and essentially use an odds-centric approach.
Can our filter be tricked? A spam message might add chunks of normal text to appear innocuous and “poison” the filter. You’ve probably seen this yourself.
What evidence should we use? Let the data speak. Email might have dozens of characteristics (time of day, message headers, country of origin, HTML tags…). Give every characteristic a likelihood factor and let Bayes sort ’em out.
Thinking With Ratios and Percentages
The ratio and percentage approaches ask slightly different questions:
Ratios: Given the odds of each outcome, how does evidence adjust them?
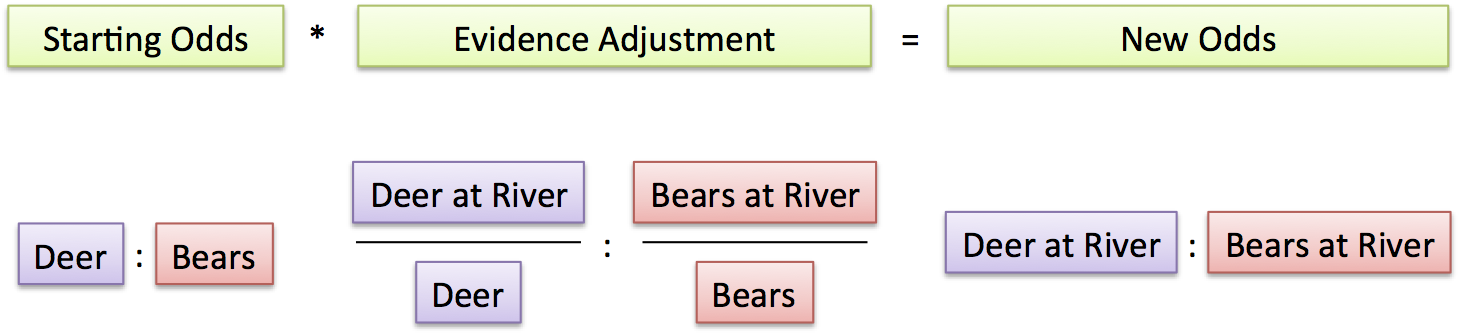
The evidence adjustment just skews the initial odds, piece-by-piece.
Percentages: What is the chance of an outcome after supporting evidence is found?
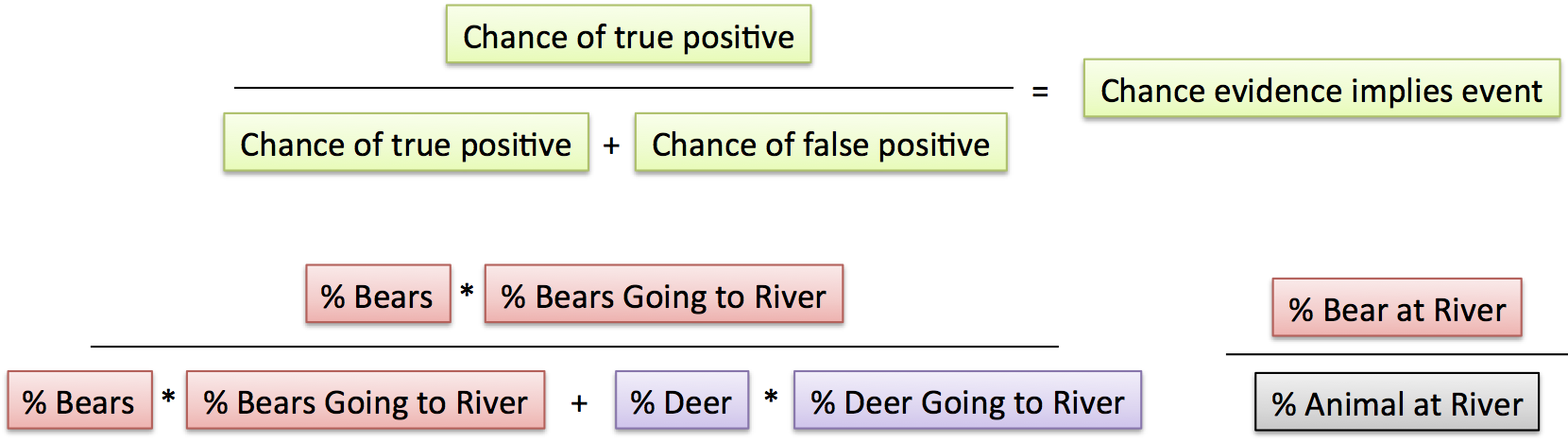
In the percentage case,
- “% Bears” is the overall chance of a bear appearing anywhere
- “% Bears Going to River” is how likely a bear is to trigger the “river” data point
- “% Bear at River” is the combined chance of having a bear, and it going to the river. In stats terms,
P(event and evidence) = P(event) * P(event implies evidence) = P(event) * P(evidence|event). I see conditional probabilities as “Chances that X implies Y” not the twisted “Chances of Y, given X happened”.
Let’s redo the original cancer example:
- 1% of the population has cancer
- 9.6% of healthy people test positive, 80% of people with cancer do
If you see a positive result, what’s the chance of cancer?
Ratio Approach:
- Cancer:Healthy ratio is 1:99
- Evidence adjustment: 80/100 : 9.6/100 = 80:9.6 (80% of sick people are “at the river”, and 9.6% of healthy people are).
- Final odds: 1:99 * 80:9.6 = 80:950.4 (roughly 1:12 odds of cancer, ~7.7% chance)
The intuition: the initial 1:99 odds are pretty skewed. Even with a 8.3x (80:9.6) boost from a positive test result, cancer remains unlikely.
Percentage Approach:
- Cancer chance is 1%
- Chance of true positive = 1% * 80% = .008
- Chance of false positive = 99% * 9.6% = .09504
- Chance of having cancer = .008 / (.008 + .09504) = 7.7%
When written with percentages, we start from absolute chances. There’s a global 0.8% chance of finding a sick patient with a positive result, and a global 9.504% chance of a healthy patient with a positive result. We then compute the chance these global percentages indicate something useful.
Let the approaches be complements: percentages for a bird’s-eye view, and ratios for seeing how individual odds are adjusted. We’ll save the myriad other interpretations for another day.
Happy math.


Leave a Reply
72 Comments on "Understanding Bayes Theorem With Ratios"
I have long had issues with “probabilities”, insofar as they are meaningless, yet people throughout society base their judgements on them – often extremely damagingly. Let me explain.
Let’s say a lottery has one million tickets. Each ticket has a one-in-a-million chance of winning, right? WRONG! ONE ticket (the winner) has 100% chance and the rest have 0%! How can all the tickets have the same chance if only one will win? That is illogical and absurd.
“Aha!” you may say, “But they each have an equal chance of winning BEFORE the winner is drawn”. But how can they each have an equal chance of winning if only one wins and the others lose – whether before or after the draw? They cannot and do not have an equal chance! Even young kids can understand that!
While one ticket in a million will win, that does NOT translate into each ticket having an equal chance!
Although most sporting events have favourites to win, quantifying their chances into odds is ridiculous, and nowhere more so than in horse racing. In the same race, one horse may be 20:1 to win, another horse 3:2, another 2:1, another 7:5 etc. – how absurd and meaningless is that, given that only one will win and the others won’t?!
Statements like “Only three other companies are bidding for the contract, so we have a one in four chance of winning it”, or “You have a 60% chance of doubling your money” are commonplace – and meaningless. Even worse, they can and do give false confidence leading to ruin, since people are misled into basing their judgements on them.
And doctors and health lobbyists should be prohibited from making such outrageous statements as “You have a one in five chance of surviving” based on data that one in five people survives. You will either survive (100%) or not (0%), so you do not have 20% chance, but either 100% or 0%. The problem is that some people literally worry themselves to death when they hear such pronouncements from doctors (who should know better, and may just be covering themselves in advance).
The error consists of extending the general to the particular (the opposite of generalising). Just because nine out of ten in my community have white skin does not mean that my skin or anyone else’s has a 90% chance of being white – it is either white or it is not!
To @ralph,
I think you concerns need to be understood in relationship to the ‘alternative model’. In this case, the alternative model is unaided intuition (expert guess) when dealing with highly complex and uncertain outcomes. All we are saying here, is that bayes can be used to model our uncertainty (put bounds on our uncertainty) not our exactness. And, there have been hundreds of studies in the pharmaceutical, soil science, military, energy and other industries that demonstrate that quantitative methods (particularly Bayesian methods) significantly out perform other methods of measurement….particularly expert opinion.
Great article in simplifying a complex subject.
As always, great post!
There are at least two additional advantages of thinking in terms of odds instead of percentages.
The first is that thinking in terms of odds reinforces the Bayesian style of probability that is the degree to which you’d feel comfortable betting on something given everything that you have observed about it so far.
The second is that using odds like you described makes a software implementation easier: you just keep track of things using simple counters. To avoid rounding errors, you can use logarithms. For example, in your second spam scenario, the logarithm of the final ratio would be
(log(9) + log(3) + log(3)) – (log(1) + log(2) + log(1)) = log(81/2)
The point is that you just keep summing logarithms on both sides of the “:” sign of the odds and then have some cutoff that determines spamminess that accounts for the pain of a false positive (i.e. make it 40:1) and then take the logarithm of that. If it exceeds the threshold then classify as spam.
Thank you, Kalid, for your fine article, and Rich for your welcome comments and Jeff for your interesting additions, on this refreshingly civil and intelligence-based site. I hasten to say that I was in no way criticizing Kalid’s excellent article in my earlier post. I was criticizing the blunt ways that “odds” and “probabilities” are used every day, often misleading people into sometimes tragic outcomes (particularly in finance/gambling and medicine). I would like to see the term “probability” replaced with “possibility” – although that may seem pedantic and trivial, I think it would more accurately reflect the truth and improve understanding. And I look forward as always to further high-quality articles and posts. Best wishes to all.
@Ralph, @Rich: Thanks for the discussion! You bring up an interesting point about the meaning of a probability — there are several interpretations, with different philosophical implications.
One interpretation is “If we repeat the experiment many times, we expect to get this outcome some known fraction of the time (i.e., coin flips)” and another is “Probability reflects our level out certainty about our knowledge” (as Rich notes).
So in the coin-flip case, we can say “I’m 50% certain that it will be heads”, which, in practical terms, means I’d be indifferent to winning 2x my money when betting on heads (better odds, like paying 3x, and I’ll play all day. Worse odds, like paying 1.5x, means I’ll never play).
There’s even more philosophical implications around Bayesian vs. Frequentist probabilities that I’m not well-versed in, but want to understand further.
@Jeff: Glad you enjoyed it — awesome insights. Yes, I think ratios/odds keep is in “probability mode” more than raw percentages (which puts my brain in “calculating” mode).
And cool note about the programming. That’s exactly it: computers have limited precision in the numbers they can represent, so drastically-shrinking percentages are a no go [in the spam case, especially, where we’ll have a multiplication by a small fraction for each word in the message!]. We can use tricks like taking the logarithm of large multiplications (i.e., adding logs) to keep numbers within reasonable bounds.
>“Aha!” you may say, “But they each have an equal chance of winning BEFORE the winner is drawn”.
Well, *I* would never say that. “Aha!” I would say instead, “But they each have an equal chance of winning BEFORE I learn the identity of the winner”. This makes it clear that lottery probabilities are facts about my knowledge about the lottery, not facts directly about the lottery itself.
My head is still not completely wrapped around Bayes Theorm yet even thought it loomed large in both the inaugural MOOC AI course taught by Thrun and Norvig and Daniel Ng’s machine learning course. As usual I can feel the wrap wrap wrapping at my brain’s door with your latest post.
@Ralph
What if we rephrased the “all tickets have equal chance to win” sentence as
“all tickets have equal chance to be the winning ticket” ?
Just wondering, if the apparent lack of meaning of probability you mentioned, is a consequence of skipping nuances while making statements.
I could be completely wrong here. I’m only an ‘amateur enthusiast’ at the maximum, regarding statistics and probability.
Thank you Kalid, for the great article.
@ AJ
Thanks for the suggestion, but to me “all tickets have (an) equal chance to be the winning ticket” and “all tickets have (an) equal chance to win” have identical meanings (and in the lottery scenario are therefore, I maintain, equally false statements).
And I now refute what I suggested earlier: ‘I would like to see the term “probability” replaced with “possibility” – although that may seem pedantic and trivial, I think it would more accurately reflect the truth and improve understanding.’ This would be equally inaccurate, since (in our lottery) only one ticket can possibly win, while the rest have zero possibility.
@Ralph
You bring up a good point. How can multiple outcomes have equal chances when only a select few will ever occur? I’m no mathematician, but there are a couple things I’d like to bring up that may prove relevant. Firstly, statistics is rather misleading in that it does not really deal with probabilities, but rather averages, and the ability to make an educated guess. Say I obtain a raffle ticket from a pool of ten tickets. What is my chance of winning the raffle? In a sense, my chance is obviously either 100% or 0% – I can’t “maybe” win the raffle. I either win or I don’t. So, in this sense, there is not much probability involved. Nine tickets have a 0% chance of winning, and one has a 100% chance of winning. Before the ticket is drawn, we can estimate the “chance” of a certain ticket winning, but the end result is the same, and so, in a roundabout sort of way, the tickets already “knew” whether they were going to win or not. But that’s not necessarily what probability is about. I know that one of the ten tickets is going to win. What probability allows me to do is decide whether getting one of these tickets is worth it. Let’s say that I repeat this process over and over; ie. I buy one raffle ticket out of ten total tickets, every time the drawing takes place. In the first drawing, one of the ten tickets wins. Fine. That may have been mine – we don’t know, as this is purely hypothetical. In the second drawing, one of the ten tickets wins (surprise!). If there are ten drawings, then I will have bought ten tickets, and, according to probability, I will have won about one raffle. Will I have actually won exactly one raffle? Probably not. But if there are one hundred drawings, then I will have bought one hundred tickets, and I will have won about ten raffles. The amount of raffles I have won is rarely ever coincident with the projected amount, but as the amount of drawings increases, the projection grows more accurate. This is what probability does: it gives us averages. Now, let’s say that the prize for the raffle is a ten dollar chocolate cake. Each ticket costs three dollars. We can use probability to figure out whether it is statistically advantageous for me to enter the drawing. If the drawing takes place one hundred times, I will have won about ten of them, giving me about $100 worth of chocolate cakes (mmm, delicious!). However, that will have meant that I spent $300 on raffle tickets. Obviously, it was not in my favor to enter the raffle – unless, of course, I won more than 30 chocolate cakes. It’s certainly possible that I did win a ridiculous amount of cakes; however, basic probability tells me that I would be better off spending my money on something more reliable. So, wouldn’t the chance of me getting back my money’s worth be 100% (if I won at least 30 cakes) or 0% (if I didn’t)? Yes, in the long run, it would. But since I didn’t have any way of seeing how many cakes I would win, use of statistics was my best bet. It’s not perfect, but it’s necessary.
Great article, thanks Khalid! Bayes can be really useful, and isn’t easy to think about.
I’d like to weigh in on the lottery thing:
Wile I certainly can’t disagree that probabilities are misused to justify bad choices, I think Ralph’s resentment of probabilities themselves is a little off-base. We’re talking about predictors here – given what we know, what are the outcomes that we can predict? Sometimes, as with Bayes and patient survival, we’re just going on prior observation, and sometimes we can calculate the exact array of possibilites, as with a lottery number. These predictors here are then used in assessment of risk, and as noted in the article, the cost of failure has to be a factor when making a decision.
I think that in society the problem usually comes not from a reliance on the odds, but from trivializing the cost of failure. Risks are taken because the odds are good, but if failure will cause an unacceptable loss (like the loss of a business, for example) then playing it safe is usually a sounder strategy.
If we’re talking about the semantics, then I think “probability” is actually a fantastic name. The possibilities in the case of a fatal disease are “I will survive this disease” and “I will die from this disease”. You can’t really ask “how possible is it that I will die?”, but you can ask “how probable (likely) is it that I will die?” And that information is valuable – if you’re likely to die, then it’s a good idea to get your affairs in order. But the really valuable information is “can I affect my chance of living?”, not “will I die?”
And a nitpick: in most lotteries, every ticket does have an equal chance to win, so long as everyone picks the same numbers. It’s perfectly possible to have more than one winning ticket – it’s the combination of numbers that can win or lose.
Ian, regarding your ‘nitpick’: you have cited a specialised lottery where you pick your numbers, and say that IF several tickets have the WINNING numbers, they have an equal chance of winning (which is obviously 100%). Although I was not referring to such lotteries which may have several winners, my argument is unchanged, and I have read nothing so far which refutes it, so will not use time and space to re-state it.
But I will point out that the recent Global Financial Crisis resulted from reliance on on “probabilities”!
On the meaning of “probability”. Is it helpful to think of a probability as meaning “my best estimate of the likelihood of something happening, based on the information available”?
So sure, only one ticket can win a lottery, but in the absence of knowing which one it is, when I buy one lottery ticket out of the million offered, MY best estimate is that I have a 1 in a million chance of that being the winning ticket.
@David: Yes, this is a much more fruitful way of looking at probability than the one proposed by Ralph Schneider. Probability is a two-place function of a fact and an observer, not a one-place function of the fact alone. That is, you don’t say that the probability that the ticket will win is one in a million; you say that the probability that the ticket will win, *given your information*, is one in a million.
Let me be clear: that one ticket in a million will win is true, but that each ticket has an equal probability of winning is false, regardless of whether someone prefaces it with “based on what I know” or “with the information I’m given”!
We need to distinguish between mathematical constructs and how we operate in ‘real life’. Obviously, we constantly operate on assumptions that things will behave as they have before – to not do so would paralyse us.
We then revise our assumptions if things do not behave as we expected (although such revisions may be misguided – for example, some may believe that the more they lose, the closer they are to winning, based on ‘the odds’!). But the obvious fact remains – what happens always had 100% chance of happening, whereas what didn’t happen always had 0% chance.
baye’s theorem demystified ;thanks a billion times
We know in advance that in our lottery only 1 ticket will win, while 999,999 will not. So it is overwhelming unlikely that any given ticket will win. That’s for sure, and it certainly indicates probability accurately, and can inform one’s choice to take a ticket or not. But to say in advance that each ticket has an equal chance, given we know in advance that only 1 will win, is nonsensical.
>it is overwhelming unlikely that any given ticket will win
This is the most sensible thing you’ve said!
@ Toby
Perhaps you could say something sensible yourself instead of catcalling from the sidelines and coming up with gibberish such as your:
“Well, *I* would never say that. “Aha!” I would say instead, “But they each have an equal chance of winning BEFORE I learn the identity of the winner”. This makes it clear that lottery probabilities are facts about my knowledge about the lottery, not facts directly about the lottery itself”.
Since you have made no intelligent or intelligible contributions, we must conclude you have none to make.
Sorry, my comment was rather curt.
It’s the most sensible thing that you’ve said, because it’s the most useful thing that you’ve said. It is (I think) the only thing that you’ve said that allows for one to actually USE probabilities other than 0 or 1, in other words to actually use probability theory in a nontrivial way.
Actually, I should have quoted more: ‘We know in advance that in our lottery only 1 ticket will win, while 999,999 will not. So it is overwhelming unlikely that any given ticket will win. That’s for sure, and it certainly indicates probability accurately, and can inform one’s choice to take a ticket or not.’. You’re not only talking about a probability that is slightly greater than 0 (in the second sentence); you’re also linking it to knowledge (in the first sentence), which is exactly how probability becomes useful (as in the third sentence). Our knowledge in advance leads us to assign, to ANY given ticket (even the one that eventually turns out to win!), the overwhelmingly unlikely probability of 0.000001 that it will win.
This directly contradicts what you wrote next: ‘But to say in advance that each ticket has an equal chance, given we know in advance that only 1 will win, is nonsensical.’. In fact, giving each ticket an equal chance is exactly what you did in the second sentence, where ANY given ticket has an overwhelmingly unlikely chance to win. And that’s exactly the sensible thing to do in advance, that is BEFORE we have any information that distinguishes the tickets. It’s only AFTER we learn which ticket won that we change this probability from 0.000001 to 0 for 999999 of the tickets, and change it from 0.000001 to 1 for 1 of the tickets.
If you’re going to use probability to make decisions, then this is how you do it, with probability depending not only on the event in question but also on the knowledge that you have at the moment.
That’s OK, Toby – I would rather have been less intemperate in my previous response, but I also wish you’d posted your latest well-reasoned and thoughtfully-written view instead of your “curt” comment, which raised my ire and made me think “why do I bother?”.
You are right, and I have never stated otherwise – BEFORE the lottery draw it SEEMS that each ticket has an equal chance and, even though we know that only one will win, we don’t know which. If the lottery were “fixed”, those who fixed it would know in advance which ticket would win, while we wouldn’t. So to the same ticket they assign 100% chance, we give only 0.0001%. So it is a question of advance knowledge – or not.
As I have prevously written, this is how we constantly make decisions, and to do so is generally “sensible”, as you say, based on what we know. But we also KNOW BEFORE the draw that 1 ticket has 100% chance and the rest have 0% – we just don’t know which.
This leads to my main point – about falsely particularising the general. While it may be true that 1 in 5 smokers will develop lung cancer, it is wrong – and certainly not “sensible” – to tell each smoker they each have an equal 1 in 5 probability, simply because we don’t know the outcome. It IS correct and sensible to tell them that 1 in 5 smokers develops lung cancer – but no more. It IS correct to say that 1 ticket in a million will win, but not – based only on our lack of foreknowledge – that each has the same chance. Again, the decisions made by bankers on the basis of “probability” led to the recent Global Financial Crisis – while they may say they acted “sensibly” on what they knew or believed (or chose to believe), others say with hindsight that they acted recklessly. Perhaps that is why these bankers have not been criminally charged – their defence is they merely acted on what they knew, or “sensibly” believed.
Ralph, you seem to be saying that the probability is SEEMINGLY 0.000001, when we have imperfect knowledge, but the probability is ACTUALLY either 0 or 1. Then using this language, it’s only the seeming probabilities, not the actual probabilities, that have any use for making decisions when one’s knowledge is incomplete (which is to say, always). And if the actual probabilities of specific events are always either 0 or 1, then we need only boolean logic to study these, not probability theory. So I would say that probability theory is really about the seeming probabilities, which are what we actually want to analyse, and so they are the only probabilities worth the name.
As for the bankers, if they really wanted to make the best decisions that they could with the information that they had, then it’s these probabilities that they should have used. It would not have been possible for them to base decisions on knowledge that they didn’t have, whatever you want to call it. Now, whether they calculated correctly, or whether they really tried to do the best, is another matter!
This is a great website! I recently bought Kalid’s book, which was also fantastic, and then I found his website, which contains a wealth of math topics explained at a very intuitive level for free. Thank you, Kalid, for providing us with such a great resource. I’m looking forward to your next book. :-)
I apologize for going off topic here, but I couldn’t find an email address or more appropriate place to post this, nevertheless, I’d like to request Kalid provide us with an intuitive explanation of Differential Equations. His calculus explanations are just so good that I really would love to read his take on Differential Equations. (Once again, sorry for being off topic.)
Hi David, no worries — I really appreciate the comment. I’d love to do some more about Diff Eqs, it’s a topic that’s bothered me for a long time (never formally studied it), but I hope to start soon. Also hoping to work on a few more books :).